
What Is RAG And Why It Matters for Legislative AI Use Cases
A plain-language explainer on an important tool for improving AI accuracy and relevance.
BY AUBREY WILSON
Conversations about AI tools for legislative or government use cases often turn to “RAG” approaches for addressing bias and hallucinations. RAG stands for Retrieval-Augmented Generation and while it sounds technical, the core concept is simple.
Commercially available AI language models (such as Anthropic’s Claude, OpenAI’s ChatGPT, Google’s Gemini, etc.) are “trained” on information available to them at the time of training. While most pro versions of models can now also search the Internet for more recent information, they still can miss important nuances, especially for narrow areas like developments in legislatures.
This is where RAG comes in.
Retrieval Augmented Generation provides a set of relevant documents to an LLM for answering a specific question.
Here is now it works:
Step 1: Making documents “readable” by AI
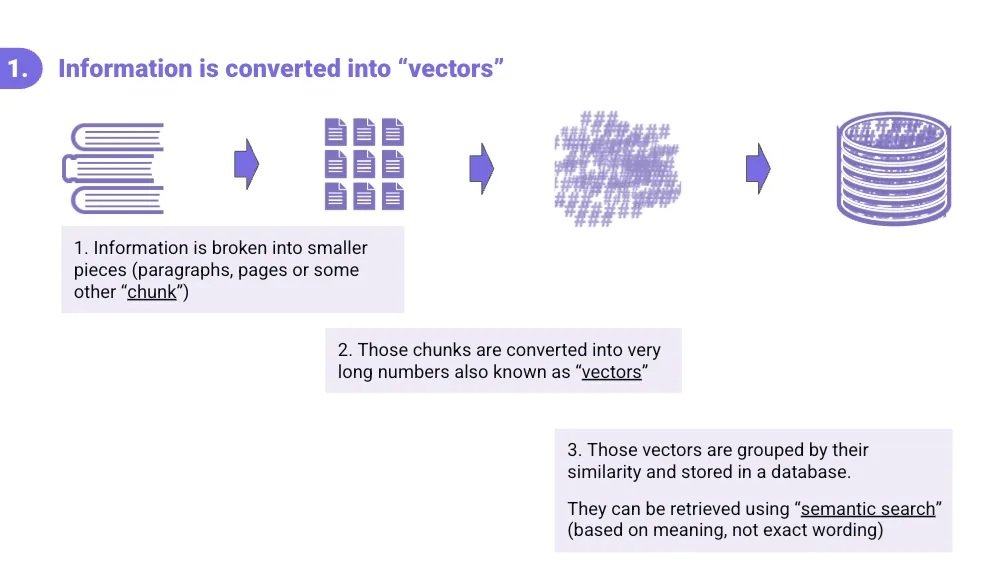
The first step in preparing documents for a RAG process is to convert text from documents such as policy documents, constituent FAQs, hearing transcripts, or legislative histories into a series of numbers or “vectors.”
Identify relevant documents: The chatbot designer will collect information they want to be available through the system. For example, if a parliament is setting up an orientation bot for new Members and staff, that collection could be a combination of procedural handbooks, maps of the parliament grounds and offices, FAQ sheets, contact lists for support offices, and HR paperwork manuals.
Chunk the documents: Once this collection of resources is collected and given to the RAG system, each document or item is broken into smaller pieces, called chunks (a paragraph, a page, or some other defined unit).
Convert to vectors: Then, each chunk is converted into a long string of numbers called a vector. Think of a vector as a kind of mathematical fingerprint that captures the meaning of a piece of text, not just its exact words.
Save in semantic database: Finally, all those vectors are stored in a database, grouped by how similar they are to each other.
This setup enables what's called semantic search: the ability to find information based on meaning, even if the query uses completely different wording than the source document.
Step 2: Use those vectors to answer a question
When a user asks a question (i.e.,: “Where can a staffer get an ID card if they lost their original?”), the system does not search for those exact words. Instead:
The question itself gets converted into a vector.
The RAG system searches the database for vectors that are semantically similar to find chunks of text that are likely to be relevant.
The system combines the prompt (instructions for how to answer questions) with the original query and a collection of semantically similar chunks of information.
This combination is sent to a Large Language Model (like Claude, ChatGPT, Grok, Gemini) through an automated programming interface, that is essentially told: “Use this information (chunks) to answer this question (query) this way (prompt).”
The AI generates a response grounded in the actual documents it was provided (in this case, the collection of onboarding materials).
The prompt can be tuned with a "temperature" setting: lower temperature means more precise and literal responses (less creative); higher temperature allows for more creative or interpretive ones. Customizing this temperature setting can be one way of minimizing the risk or likelihood of hallucinations by the system.

A real world example
RAG systems are not theoretical; they are actively being used by institutions and industries around the globe. At POPVOX Foundation, we created a RAG bot to demonstrate the above use case: an AI bot called StaffLink. StaffLink is trained on various publicly available onboarding materials for junior staff in the US Congress. You can interact with StaffLink at stafflinkbot.org.
Why RAG matters for legislative institutions
RAG is one approach to deploying AI technology in areas that require a high degree of accuracy and control. RAG-powered tools can draw on your documents, your policies, and your institutional knowledge.
That means:
a training tool for new staff and Members that pulls from verified, current materials like handbooks or orientation manuals (the example used above),
a constituent services chatbot that actually reflects your office's procedures or policies, or
a research assistant that can answer questions about specific legislation accurately.
Systems utilizing a RAG approach offer more accountability and transparency. Because the AI is working from a defined set of documents, it is easier to verify where an answer came from and catch errors when they occur. RAG systems can also be set to require citations and links to source documents.
The reliability and accuracy of RAG-based systems depend on the quality of documents provided, the effectiveness of the chunking and vectorizing process, the LLM used to process queries, and the system prompt guiding the process. These are all things that can be tested and refined over time to improve the performance of the system.
Understanding how RAG and other varieties of AI tools work is valuable for legislators and staff, and vital in helping parliamentary institutions keep pace during this time of rapid technological change.